Normalization
normalization¶
各种归一化算法很多:
Batch Normalization (BN)
layer-normalization Layer Normalization (LN)
Instance Normalization (IN)
Group Normalization (GN)
weight-normalization
spectral-normalization
tutorial¶
非常详细的推荐: https://zhuanlan.zhihu.com/p/33173246
简明扼要的: https://zhuanlan.zhihu.com/p/86765356 (内容已复制到这里)
why¶
把每层的输入值分布强行拉回到均值为0,方差为1的标准正态分布
tldr¶
让该层参数稳定下来,避免梯度消失或者梯度爆炸,加快收敛、训练速度
bn
- bn对除channel外的所有维做归一化
- 得到C通道(类似特征)个均值和方差
- 推理时可以做参数融合加快推理速度
- 对 batch 大小敏感
ln
- ln对除batch外的所有维做归一化(nlp中只对channel做归一化,不同场景下不同,这个要注意!)
- 不受 batch size/句子长度影响,适用于RNN
- 如果不同输入特征不属于相似的类别(比如颜色和大小),那么 LN 的处理可能会降低模型的表达能力。
- 一个可信的直观解释:nlp中emmbedding并不存在一个客观的分布,相反我们需要考虑的是:我们希望得到一个符合什么样分布的embedding?
- 很好理解,通过layer normalization得到的embedding是 以坐标原点为中心,中空的球形环状分布,越往两侧越稀疏的环形球体空间中。
但是还是“实践出真知”2022各种Vision Transformers中也用的LayerNorm,CNN也可以用layernorm
summary¶
其实都差不多,减去均值,除以标准差,再做一次线性变换
主要区别在于操作的 feature map 维度不同
Batch Normalization¶
result: 得到 C 个均值,C 为通道数
常用于 CNN,对 batch size 敏感
nn.BatchNorm2d()
差不多是效果最好的,feature map: \(x \in \mathbb{R}^{N \times C \times H \times W}\),包含 N 个样本,
每个样本通道数为 C,高为 H,宽为 W。对其求均值和方差时,将在 N、H、W上操作,而保留通道 C 的维度。具体来说,就是把第1个样本的第1个通道,加上第2个样本第1个通道 …… 加上第 N 个样本第1个通道,求平均,得到通道 1 的均值(注意是除以 N×H×W 而不是单纯除以 N,最后得到的是一个代表这个 batch 第1个通道平均值的数字,而不是一个 H×W 的矩阵)。求通道 1 的方差也是同理。对所有通道都施加一遍这个操作,就得到了所有通道的均值和方差。具体公式为:
ps: 这里只是粗糙的公式,细节计算见: https://zhuanlan.zhihu.com/p/120265831
如果把 \(x \in \mathbb{R}^{N \times C \times H \times W}\) 类比为一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 W 个字符。BN 求均值时,相当于把这些书按页码一一对应地加起来(例如第1本书第36页,第2本书第36页……),再除以每个页码下的字符总数:N×H×W,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字),求标准差时也是同理。
# normalization
import torch
from torch import nn
# track_running_stats=False,求当前 batch 真实平均值和标准差,
# 而不是更新全局平均值和标准差
# affine=False, 只做归一化,不乘以 gamma 加 beta(通过训练才能确定)
# num_features 为 feature map 的 channel 数目
# eps 设为 0,让官方代码和我们自己的代码结果尽量接近
bn = nn.BatchNorm2d(num_features=3, eps=0, affine=False, track_running_stats=False)
# 乘 10000 为了扩大数值,如果出现不一致,差别更明显
x = torch.rand(10, 3, 5, 5)*10000
official_bn = bn(x)
# 把 channel 维度单独提出来,而把其它需要求均值和标准差的维度融合到一起
x1 = x.permute(1,0,2,3).view(3, -1)
mu = x1.mean(dim=1).view(1,3,1,1)
# unbiased=False, 求方差时不做无偏估计(除以 N-1 而不是 N),和原始论文一致
# 个人感觉无偏估计仅仅是数学上好看,实际应用中差别不大
std = x1.std(dim=1, unbiased=False).view(1,3,1,1)
my_bn = (x-mu)/std
diff=(official_bn-my_bn).sum()
print('diff={}'.format(diff)) # 差别是 10-5 级的,证明和官方版本基本一致
为什么会带来随机性¶
Batch normalization 的主要目的是减少神经网络中深层层次之间的共变量转移,以及减轻梯度消失和梯度爆炸的问题。在进行训练时,batch normalization 除了对每个 mini-batch 进行归一化之外,还会进行平移和缩放操作。这些参数平移和缩放操作会引入额外的随机性,因为每个 mini-batch 的统计信息都不同, 与之对比的是采用全局平均值和方差。
此外,由于 batch normalization 是在 mini-batch 上计算的,因此即使对于相同的输入数据,也可能在不同的训练迭代之间产生不同的结果。这也会带来额外的随机性。因此,batch normalization 可以带来一些随机性,并使每个 mini-batch 中的数据具有不同的统计特征。
为什么不采用全局统计值¶
采用全局平均值和方差进行归一化并不是一个好的选择,因为使用全局统计信息可能会使网络对于输入的小变化变得过于敏感,导致过拟合的情况出现。这是因为全局平均值和方差对于输入数据的整体分布特征进行归一化,可能会将一些特有的、局部的信息抹掉。另外,使用全局统计信息进行归一化也不利于模型的移植,因为对于不同的数据集,它们的分布特征可能是不同的,因此使用全局的统计信息并不一定是最好的选择。因此,使用每个 mini-batch 的统计信息进行归一化是比较合理的选择,可以使每个 mini-batch 中的数据具有不同的统计特征,并且不容易过拟合。
滑动平均¶
在训练过程中,为保持稳定,一般使用滑动平均法更新均值和方差,滑动平均就是在更新当前值的时候,以一定比例保存之前的数值,以均值 \(\mu\)\mu 为例,以一定比例 \(\theta\)\theta (例如这里0.99)保存之前的均值,当前只更新 \((1- \theta )\)(1- \theta ) 倍(也就是0.001倍)的本Batch的均值,计算方法如下:
\(\mu_{i}=\theta\mu_{i-1} + (1-\theta)\mu_{i}\)
标准差的滑动平均计算方法也一样。
推理-做参数融合-加入¶
见: https://zhuanlan.zhihu.com/p/120265831
5%提速 + 节省内存
因为推理时,BN是一个线性的操作,也就是一个缩放+一个偏移,我们完全可以把这个线性操作叠加到前面的全连接层或者卷积层,只需要把全连接或者卷积层的权重乘以一个系数 \(a\)a ,偏置从 \(c\)c 变为 \(ac+b\)ac+b 就可以了了
融合BN仅限于Conv+BN或者是BN+Conv结构,中间不能加非线性层,例如Conv+ReLu+BN那就不行了。当然,一般结构都是Conv+BN+ReLu结构。
Layer Normalization¶
result:
CV: 中得到 N 个均值, N 为样本/batch_size个数,对 C + H + W 上做归一化
NLP: 中得到(batch, seq_size)个,相当于对 emb或者hidden_size 上做归一化在图像问题中,LN是指对一整张图片进行标准化处理,即在一张图片所有channel的pixel范围内计算均值和方差。而在NLP的问题中,LN是指在一个句子的一个token的范围内进行标准化
BN 的一个缺点是需要较大的 batchsize 才能合理估训练数据的均值和方差,这导致内存很可能不够用,同时它也很难应用在训练数据长度不同的 RNN 模型上。Layer Normalization (LN) 的一个优势是不需要批训练,在单条数据内部就能归一化。
对于 \(x \in \mathbb{R}^{N \times C \times H \times W}\),LN 对每个样本的 C、H、W 维度上的数据求均值和标准差,保留 N 维度。其均值和标准差公式为:
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-12):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
var = x.var(-1, unbiased=False, keepdim=True)
# '-1' means last dimension.
out = (x - mean) / torch.sqrt(var + self.eps)
out = self.gamma * out + self.beta
return out
继续采用上一节的类比,把一个 batch 的 feature 类比为一摞书。LN 求均值时,相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W,即求整本书的“平均字”,求标准差时也是同理。
注意 在 seq 模型中 Layer normalization 的输入和输出的维度都为(batch_size, sequence_length, hidden_size),其中:
- batch_size:一次训练或推断时输入数据的样本数。
- sequence_length:输入序列的长度,对于Transformer来说就是指单词序列的长度。
- hidden_size:隐藏层的大小,即向量的维度。
Layer normalization是对隐藏状态向量的最后一个维度(hidden_size)进行归一化的。
如下代码对比了 pytorch 官方 API 计算 LN,和依据原理逐步计算 LN 得到的结果:
import torch
from torch import nn
x = torch.rand(10, 3, 5, 5)*10000
# normalization_shape 相当于告诉程序这本书有多少页,每页多少行多少列
# eps=0 排除干扰
# elementwise_affine=False 不作映射
# 这里的映射和 BN 以及下文的 IN 有区别,它是 elementwise 的 affine,
# 即 gamma 和 beta 不是 channel 维的向量,而是维度等于 normalized_shape 的矩阵
ln = nn.LayerNorm(normalized_shape=[3, 5, 5], eps=0, elementwise_affine=False)
official_ln = ln(x)
x1 = x.view(10, -1)
mu = x1.mean(dim=1).view(10, 1, 1, 1)
std = x1.std(dim=1,unbiased=False).view(10, 1, 1, 1)
my_ln = (x-mu)/std
diff = (my_ln-official_ln).sum()
print('diff={}'.format(diff)) # 差别和官方版本数量级在 1e-5
Instance Normalization¶
得到 N * C 个均值,只在 H x W 上操作
IN一般用于生成任务和风格迁移任务,因为这种任务会对细节特征有高要求,直观可以理解为更细粒度的特征区分要求
Instance Normalization (IN) 最初用于图像的风格迁移。作者发现,在生成模型中, feature map 的各个 channel 的均值和方差会影响到最终生成图像的风格,因此可以先把图像在 channel 层面归一化,然后再用目标风格图片对应 channel 的均值和标准差“去归一化”,以期获得目标图片的风格。IN 操作也在单个样本内部进行,不依赖 batch。
对于 \(x \in \mathbb{R}^{N \times C \times H \times W}\),IN 对每个样本的 H、W 维度的数据求均值和标准差,保留 N 、C 维度,也就是说,它只在 channel 内部求均值和标准差,其公式为:
IN 求均值时,相当于把一页书中所有字加起来,再除以该页的总字数:H×W,即求每页书的“平均字”,求标准差时也是同理。
如下代码对比了 pytorch 官方 API 计算 IN,和依据原理逐步计算 IN 得到的结果:
import torch
from torch import nn
x = torch.rand(10, 3, 5, 5) * 10000
# track_running_stats=False,求当前 batch 真实平均值和标准差,
# 而不是更新全局平均值和标准差
# affine=False, 只做归一化,不乘以 gamma 加 beta(通过训练才能确定)
# num_features 为 feature map 的 channel 数目
# eps 设为 0,让官方代码和我们自己的代码结果尽量接近
In = nn.InstanceNorm2d(num_features=3, eps=0, affine=False, track_running_stats=False)
official_in = In(x)
x1 = x.view(30, -1)
mu = x1.mean(dim=1).view(10, 3, 1, 1)
std = x1.std(dim=1, unbiased=False).view(10, 3, 1, 1)
my_in = (x-mu)/std
diff = (my_in-official_in).sum()
print('diff={}'.format(diff)) # 误差量级在 1e-5
Instance Normalization: The Missing Ingredient for Fast Stylization
<https://arxiv.org/abs/1607.08022>__.
$$
y = \frac{x - \mathrm{E}[x]}{ \sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta
$$
主要看 torch 代码里头的注释
Group Normalization¶
得到 N * G 个数值,其中 G < C,因为 Group 是对 C 的分组
Group Normalization (GN) 适用于占用显存比较大的任务,例如图像分割。对这类任务,可能 batchsize 只能是个位数,再大显存就不够用了。而当 batchsize 是个位数时,BN 的表现很差,因为没办法通过几个样本的数据量,来近似总体的均值和标准差。GN 也是独立于 batch 的,它是 LN(G=C) 和 IN(G=1)的折中, 。正如提出该算法的论文展示的:
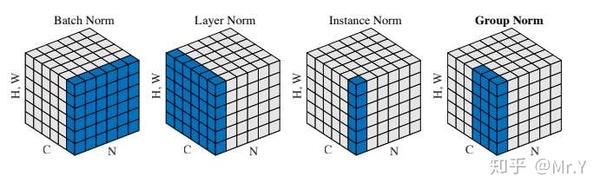
GN 计算均值和标准差时,把每一个样本 feature map 的 channel 分成 G 组,每组将有 C/G 个 channel,然后将这些 channel 中的元素求均值和标准差。各组 channel 用其对应的归一化参数独立地归一化。
继续用书类比。GN 相当于把一本 C 页的书平均分成 G 份,每份成为有 C/G 页的小册子,求每个小册子的“平均字”和字的“标准差”。
如下代码对比了 pytorch 官方 API 计算 GN,和依据原理逐步计算 GN 得到的结果:
import torch
from torch import nn
x = torch.rand(10, 20, 5, 5)*10000
# 分成 4 个 group
# 其余设定和之前相同
gn = nn.GroupNorm(num_groups=4, num_channels=20, eps=0, affine=False)
official_gn = gn(x)
# 把同一 group 的元素融合到一起
x1 = x.view(10, 4, -1)
mu = x1.mean(dim=-1).reshape(10, 4, -1)
std = x1.std(dim=-1).reshape(10, 4, -1)
x1_norm = (x1-mu)/std
my_gn = x1_norm.reshape(10, 20, 5, 5)
diff = (my_gn-official_gn).sum()
print('diff={}'.format(diff)) # 误差在 1e-4 级
weight normalization WN¶
- tutorial: https://www.bilibili.com/video/BV1NZ4y117VT/
https://pytorch.org/docs/stable/generated/torch.nn.utils.weight_norm.html
https://zhuanlan.zhihu.com/p/55102378
https://arxiv.org/abs/1602.07868
Weight Normalization
对于人工神经网络中的一个神经元来说,其输出y yy表示为:
\(y=\phi(\boldsymbol{wx}+b)\)
其中\(\boldsymbol{w}\) 是k维权重向量,b是标量偏差,x是k维输入特征,\(\phi(.)\)是激活函数。
WN的重参数表示:对权重w \bm{w}w用参数向量v和标量g进行表示,则新参数表示为:
\(\(\boldsymbol{w}=\frac{g}{\|\boldsymbol{v}\|}\boldsymbol{v}\)\)
我们可以发现\(\|\boldsymbol{w}\| =g\),与参数v独立,而权重w的方向也变更为\(\frac{v}{\|\boldsymbol{v}\|}\)
WN的做法是将权值向量 \(W\)
在其欧氏范数和其方向上解耦成了参数向量 \(\vec{v}\) \(\boldsymbol{v}\) 和参数标量 \(g\)
后使用SGD分别优化这两个参数。
weight_g、weight_v都会进行更新,各自独立更新,文中解释了,这样更新比单独更新W会更加稳定训练。
WN也是和样本量无关的,所以可以应用在batchsize较小以及RNN等动态网络中;另外BN使用的基于mini-batch的归一化统计量代替全局统计量,相当于在梯度计算中引入了噪声。而WN则没有这个问题,所以在生成模型,强化学习等噪声敏感的环境中WN的效果也要优于BN。
WN没有一如额外参数,这样更节约显存。同时WN的计算效率也要优于要计算归
在 hifigan 中用到!
推理-remove weight norm¶
训练的时候拆分为幅度值和方向向量单独进行反向传播,但是推理的时候并不需要,融合回 weight 就行
Spectral Normalization 谱归一化¶
tutorial¶
https://zhuanlan.zhihu.com/p/63957812
note¶
用于 gan 的 discriminator 中 : https://github.com/wenet-e2e/wetts/blob/main/wetts/vits/models.py#L364 不过 vits 中默认配置为 False,也就是默认采用 weight norm
谱范数,也称为矩阵二范数,是一种常用的矩阵范数,它是矩阵特征值的平方根的最大值。通过谱范数,可以测量矩阵的大小和对于向量的影响程度。谱范数在矩阵分析、计算机科学、信号处理和机器学习等领域中广泛应用。
Spectral normalization for generative adversarial network” (以下简称 Spectral Norm) 使用一种更优雅的方式使得判别器 D 满足利普希茨连续性,限制了函数变化的剧烈程度,从而使模型更稳定。
矩阵\(A\)(或者说网络的权重)除以它的 spectral norm(\(A^TA\)最大特征值的开根号\(\sqrt{\lambda_1}\))可以使其具有 1-Lipschitz continuity。(证明在这里谱归一化)
判别器 D 使用了 Spectral norm 之后,就不能使用 BatchNorm (或者其它 Norm) 了。 原因也很简单,因为 Batch norm 的“除方差”和“乘以缩放因子”这两个操作很明显会破坏判别器的 Lipschitz 连续性。
总结¶
这里再重复一下上文的类比。如果把 \(x \in \mathbb{R}^{N \times C \times H \times W}\) 类比为一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 W 个字符。
计算均值时,
BN 相当于把这些书按页码一一对应地加起来(例如:第1本书第36页,加第2本书第36页……),再除以每个页码下的字符总数:N×H×W,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字)
LN 相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W,即求整本书的“平均字”
IN 相当于把一页书中所有字加起来,再除以该页的总字数:H×W,即求每页书的“平均字”
GN 相当于把一本 C 页的书平均分成 G 份,每份成为有 C/G 页的小册子,对这个 C/G 页的小册子,求每个小册子的“平均字”
计算方差同理。
此外,还需要注意它们的映射参数 \gamma 和 \beta 的区别:对于 BN,IN,GN, 其 \gamma 和 \beta 都是维度等于通道数 C 的向量。而对于 LN,其 \gamma 和 \beta 都是维度等于 normalized_shape 的矩阵。
最后,BN 和 IN 可以设置参数: momentum 和 track_running_stats来获得在全局数据上更准确的 running mean 和 running std。而 LN 和 GN 只能计算当前 batch 内数据的真实均值和标准差。
除了上面这些归一化方法,还有基于它们发展出来的算法,例如 Conditional BatchNormalization 和 AdaIN,可以分别参考下面的解释:
Conditional Batch Normalization详解
https://zhuanlan.zhihu.com/p/61248211
从Style的角度理解Instance Normalization
https://zhuanlan.zhihu.com/p/57875010
nn.instanceNorm2d¶
听说在GAN网络中,这种效果要比 BatchNorm 好
- batch size 和 learning rate 设置的影响
- 【AI不惑境】学习率和batchsize如何影响模型的性能? - 知乎
- 更大的batch size 说明你对梯度下降的方向更加肯定,所以lr 可以更大(迈开的步伐更大)
bn对除channel外的所有维做归一化,ln对除batch外的所有维做归一化
Created : 2023年12月4日